
Project B11:
Semantic roles, case relations, and cross-clausal reference in Tibetan
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
Warning:
due to technical problems with the host server, the dynamic and searchable cocoon representation of our annotations (text plus translation plus various information) as developed by Frank M�ller-Witte is currently out of work. We, nevertheless, keep the description of what has been possible in the past and what could perhaps become functional again some time in the future.
The non searchable and static tree views (png) can still be visited. They are provided with an interlinear version, instead of a translation. These representations had to be segmented and prepared separately for a) the reference and frame structure and b) the clause structure with full element descriptions (see introductiory note).
BZ 20.12.2009.
Visible corpora
 As one can see from our two
annotation examples, one for Old Tibetan and one
for Ladakhi, the mere
xml-structure is hardly informative and of
little use for a person not acquainted with computer linguistics. Even
when the tags and their content can be differentiated (e.g. by
colours), the annotated texts gets completely lost in the tag forest.
As the
available linguistic representation tools could not handle our complex
text structures, we experimented with some alternative representations.
One of the main
problems we faced is that most solutions, especially those based on
java tools, are far too slow for the (little) amount of text that
we have so far produced.
As one can see from our two
annotation examples, one for Old Tibetan and one
for Ladakhi, the mere
xml-structure is hardly informative and of
little use for a person not acquainted with computer linguistics. Even
when the tags and their content can be differentiated (e.g. by
colours), the annotated texts gets completely lost in the tag forest.
As the
available linguistic representation tools could not handle our complex
text structures, we experimented with some alternative representations.
One of the main
problems we faced is that most solutions, especially those based on
java tools, are far too slow for the (little) amount of text that
we have so far produced. The main representation, developed by Frank M�ller-Witte with the help of Fabian Kliebhahn, runs under a cocoon application on an auxiliary server without exposing the xml-data to the viewer. It shows a field for the Tibetan text (unstructured or with brackets for four consecutive embedded structures), a field for the translation, additional information on clause structures, or a representation of the tree structure.
 The
translation
becomes visible when clicking on the red verb number.
All verbs in the translation are linked to their Tibetan counterparts
in the original text, which makes it easy to navigate. Green brackets
indicate ntNodes (argument NPs or adverbial phrases, AvPs), clauses are
indicated by blue
brackets. Information concerning the clause structure
becomes visible when clicking on the blue opening bracket. The clause
type is indicated directly after the closing blue bracket, and clicking
on this category will open up the tree display for this clause. The
page is can be searched through in the normal search mode, an
x-path-search is, for the time being, not possible. For the Tibetan
text you may need the
following special signs: �, ŋ, �, �, �, ḥ, in Names: Ŋ, �, �, �, Ḥ, for words of Indian origin, additionally ṭ, ḍ, ṇ, ś, ṣ, Ś.
The
translation
becomes visible when clicking on the red verb number.
All verbs in the translation are linked to their Tibetan counterparts
in the original text, which makes it easy to navigate. Green brackets
indicate ntNodes (argument NPs or adverbial phrases, AvPs), clauses are
indicated by blue
brackets. Information concerning the clause structure
becomes visible when clicking on the blue opening bracket. The clause
type is indicated directly after the closing blue bracket, and clicking
on this category will open up the tree display for this clause. The
page is can be searched through in the normal search mode, an
x-path-search is, for the time being, not possible. For the Tibetan
text you may need the
following special signs: �, ŋ, �, �, �, ḥ, in Names: Ŋ, �, �, �, Ḥ, for words of Indian origin, additionally ṭ, ḍ, ṇ, ś, ṣ, Ś. Two
additional
minor
fields on the right side should ideally provide
lexical information from the accompanying text- specific dictionaries,
when clicking on a word in the Tibetan text.
Notes to the annotation or the context are indicated by an asterisk,
which can be clicked upon to access the information in the form of a
system message (see also the small graphic above). Time constraints
did not allow optimising the representation
technically and aesthe- tically, and we thus apologise for any
instance,
where these fields do not function properly, due to either a minor
fault in programming (FMW) or in the annotation (BZ).
Two
additional
minor
fields on the right side should ideally provide
lexical information from the accompanying text- specific dictionaries,
when clicking on a word in the Tibetan text.
Notes to the annotation or the context are indicated by an asterisk,
which can be clicked upon to access the information in the form of a
system message (see also the small graphic above). Time constraints
did not allow optimising the representation
technically and aesthe- tically, and we thus apologise for any
instance,
where these fields do not function properly, due to either a minor
fault in programming (FMW) or in the annotation (BZ). As the application can no longer be hosted on the SFB server; the set up on the new host server is under preparation. The contact person for this application will be Frank M�ller-Witte (email: frank.mueller-witte[ ]uni-tuebingen.de). For details of the annotation you may contact Bettina Zeisler (email: zeis[ ]uni-tuebingen.de). Note that the representation has been adapted only to Firefox and may not function properly in other browsers.
Four small corpora are presently available:
Old Tibetan:
OTC: The Old Tibetan Chronicle Chapter I
RAMA: Fragments of the Tibetan Rāmāyaṇa (preliminary annotation)
Classical Tibetan:
TVP: Die tibetische Version des Papageienbuchs
Contemporary Ladakhi:
LLV: A Lower Ladakhi version of the Kesar epic
see also the metadata below.
| top project page field work publications documentation of the annotation scheme |
presentation note on translations metadata tree views CLaRK tree representations (overview) |
A note on the translations
All corpora are supplied with translations for those readers who are not well acquainted with Tibetan. It was not our aim to provide new translations, nor did we have enough time for this task. For this reason we provide the original translations, which, in two cases, happen to be in German. While the translation of the LLV by Anna Theodora Francke needed only small changes to fit into the annotation scheme, the translation of the TVP by Silke Herrmann turned out to be quite problematic and we had to interfere more often than we wished. We have nevertheless kept as much of her translation as possible, respecting the freedom of the author, without, however, underwriting all her solutions. Our changes are marked by square brackets.
Similarly, we had planned to use Bacot et al.'s French translation of the OTC. Nathan W. Hill, however, whose main task was the annotation of OTC, was eager to provide a new translation, and since the OTC constitutes a particularly difficult text, this was accepted on the condition that the translation reflects the annotation (or vice versa) so that the translation could be a useful tool in the process of annotating. Unfortunately his translation (published 2006 in the Revue d'Etudes Tib�taines 10: 89-101) does not reflect the annotation. According to the intentions of the author (cf. p. 89, note 2), it also does not, with only one exception, reflect any of the discussions in the project. Since the earlier, pioneering translations, were, at crucial points, also not much better, we eventually decided to provide yet another translation, a translation, however, which does not strive for literary elegance and originality, but is as faithful to the structure of the original as possible. Thus no attempt was made to smoothen out the long chains of intertwining non-finite clauses. We think, however, that this representation has at least the benefit to immediately show the different strategies of representation, such as the mere enumeration of (possibly historical) facts in short simple sentences in � 6, which stands in sharp contrast to the more condensed and complex mythological narration in � 5, which consists of only few sentences, but a lot of embedded structures. Like in literary German, complex sentences may be helpful to represent complex situations, but they may also be used to veil facts and reasons (or the absence of these). And they may be prone to linguistic accidents.
Despite, or perhaps because of, sticking slavishly to the text and the grammatical rules, we came in several cases to quite different interpretations than the previous translators. Since our linguistic as well as historical insights might be of some interest to the students of Tibetan history, we shall provide here in advance a version of the annotated translation as pdf.
| top project page field work publications documentation of the annotation scheme |
presentation note on translations metadata tree views CLaRK tree representations (overview) |
Metadata
(If diacritics are not properly displayed, select the UTF-8 charset on your browser.)
|
Language |
Siglum |
Text |
Annotators |
|
Old Tibetan ca. mid
7th � mid 11th century |
OTC |
Fonds Pelliot Ms.
250 / Pelliot tib�tain 1287, |
Responsible for the
annotation: Bettina Zeisler (BZ), |
|
Sources |
Annotated text |
||
|
First publication: Bacot & al. 1940: 97-122. |
Chapter I (l. 1-62; Bacot & al. pp. 97-100; Macdonald
& Imaeda, pl. 557-559, Imaeda & al.: 200-202) |
||
|
RAMA |
Text |
Annotators |
|
|
Short version of the Indic epos Rāmāyaṇa several fragments of
basically two recensions (Biblioth�que Nationale de France and British
Library), probably late 9th or 10th century |
Preliminary annotation: Bettina Zeisler with input from
Nicola Westermann |
||
|
Sources |
Annotated text |
||
|
Text and translation: |
92 clauses of fragment E |
||
|
Language |
Siglum |
Text |
Annotators |
|
Classical Tibetan
ca. 11th � 19th century |
TVP |
Die tibetische
Version des Papageienbuches, a 15th
century adaptation of the Indian narrations of the parrot,
styled as stories about previous reincarnations of Atisha and his
disciples. |
Responsible for the annotation: Bettina Zeisler (BZ), |
|
Sources |
Annotated text |
||
|
Text and translation: |
ca. 40% (fol. 261v1 - 268v5, pp. 43-48) |
||
|
Language |
Siglum |
Text |
Annotators |
|
contemporary
Ladakhi, West Tibetan |
LLV |
G�amyulna
b�adpaḥi Kesargyi sgruŋs b�ugs. A Lower Ladakhi version of the Kesar saga, collected around 1900. |
Digitalisation (typing): Namgyal Nyima Dagkar (Bonn) |
|
Sources |
Annotated text |
||
|
Text: Francke, August Hermann. 1905-41. Translation: Francke, Anna Theodora. 1992. |
Chapter I (pp. 1-16) |
References
| top project page field work publications documentation of the annotation scheme |
presentation note on translations metadata tree views CLaRK tree representations (overview) |
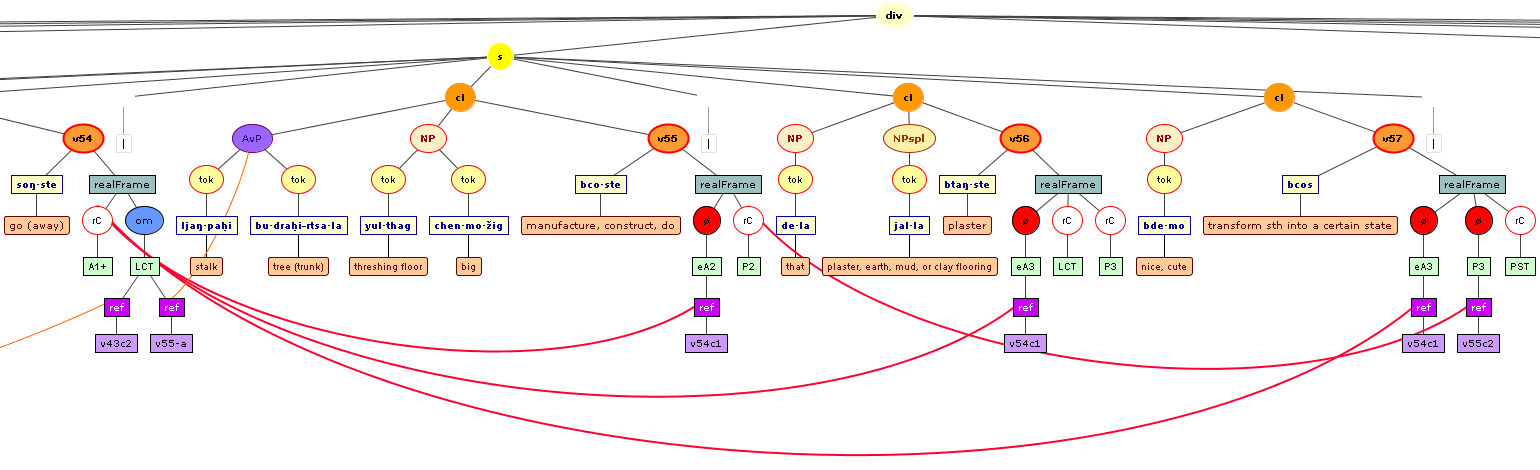
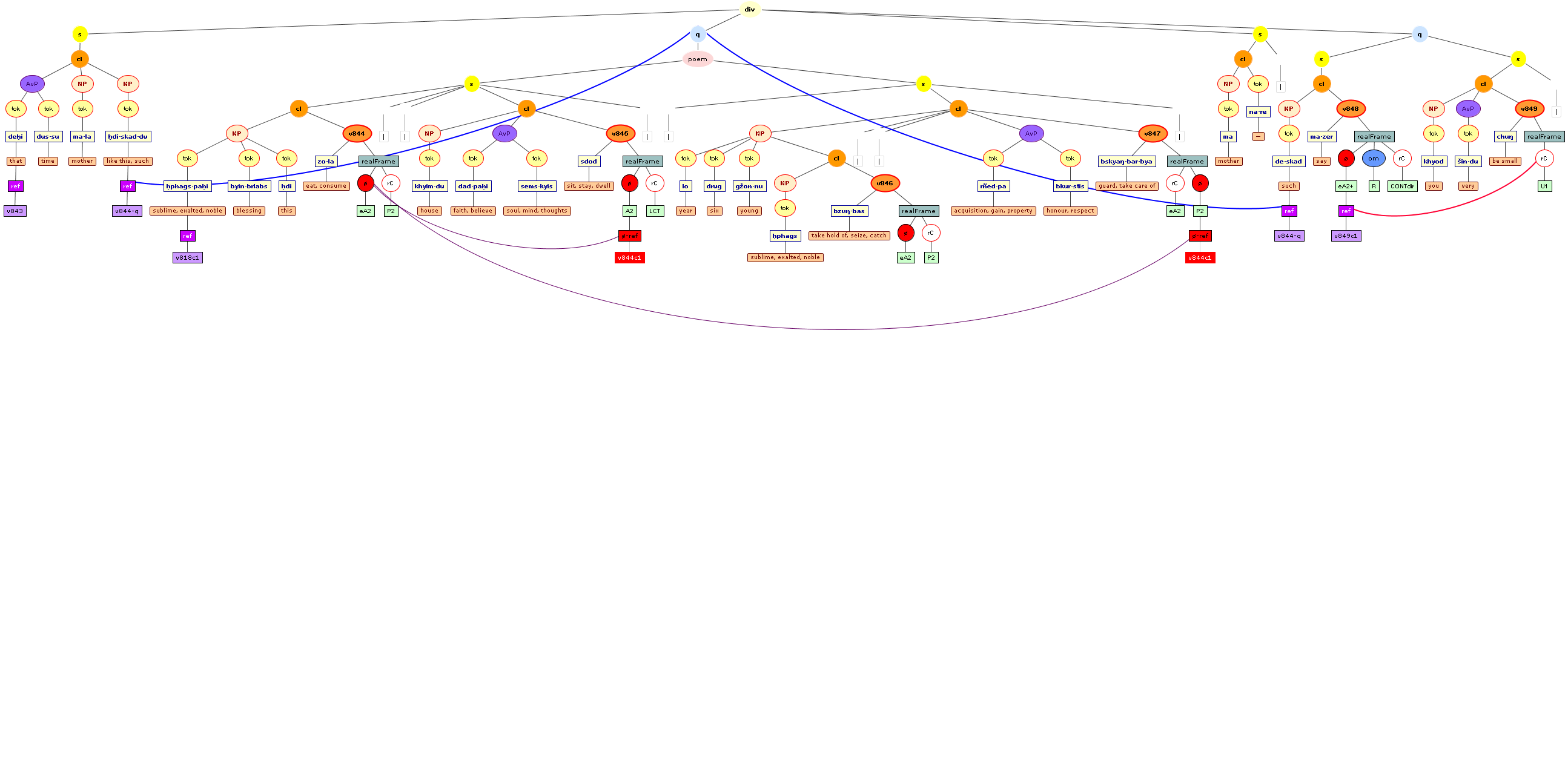
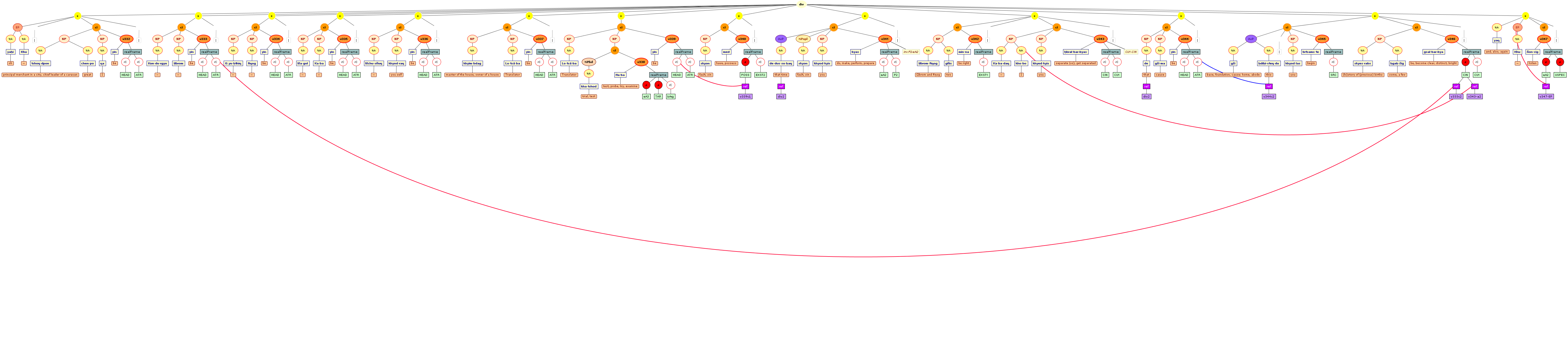
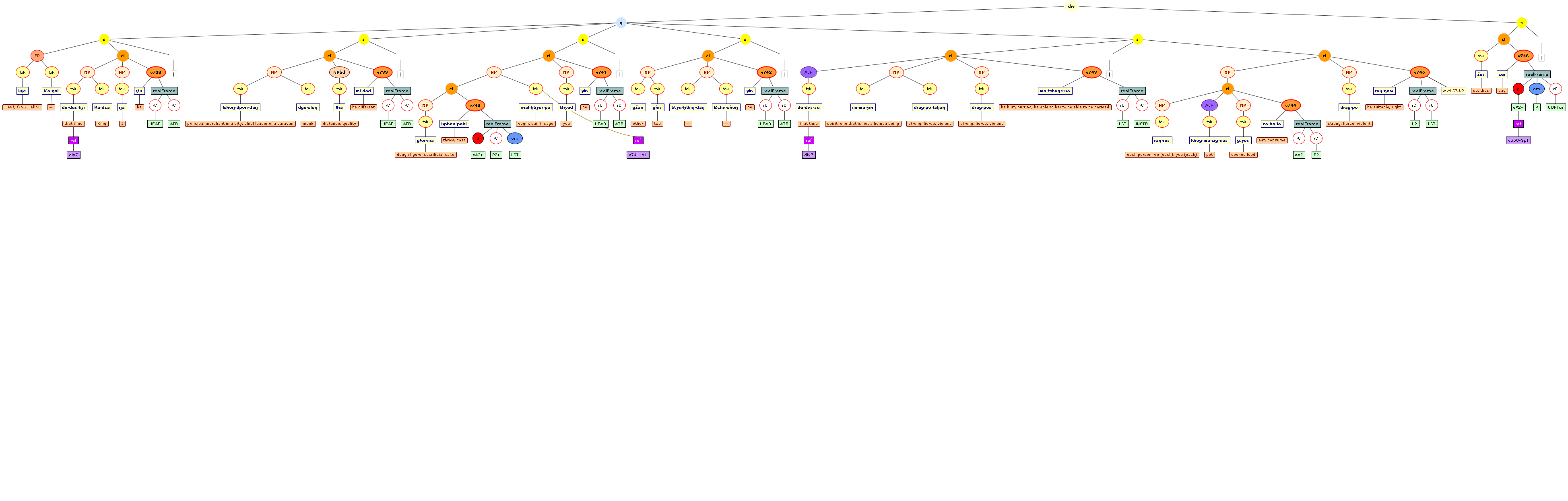
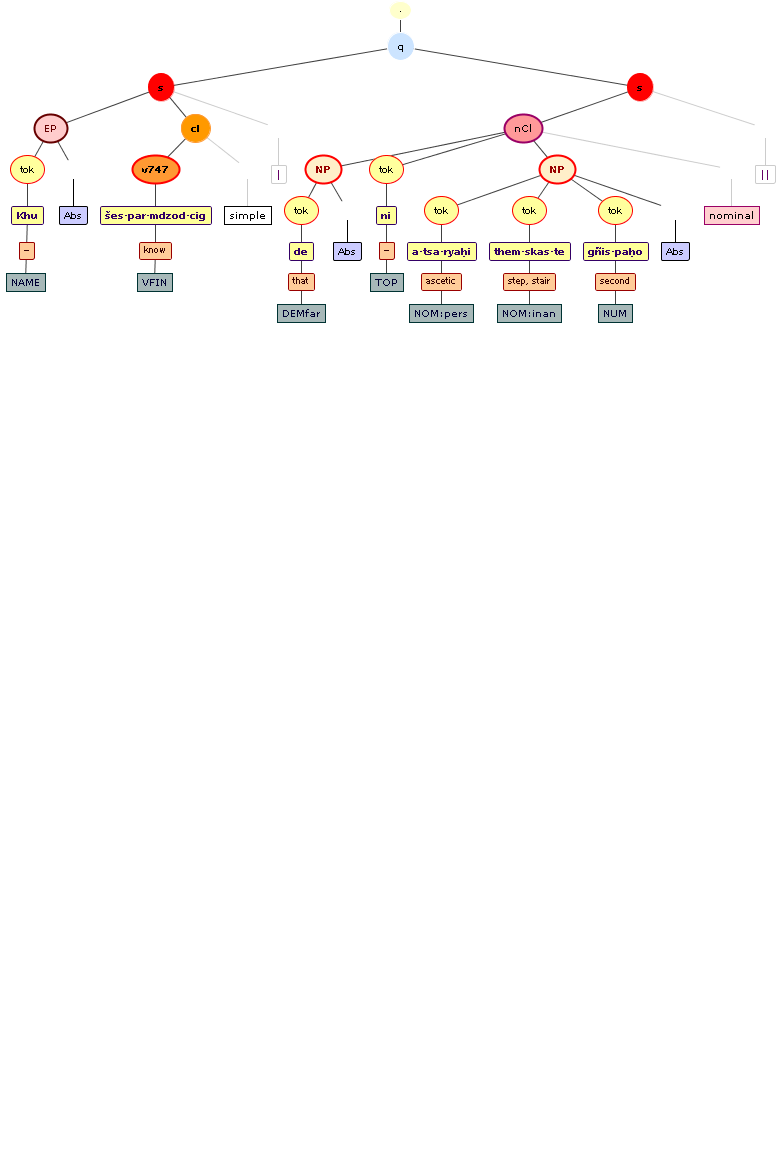
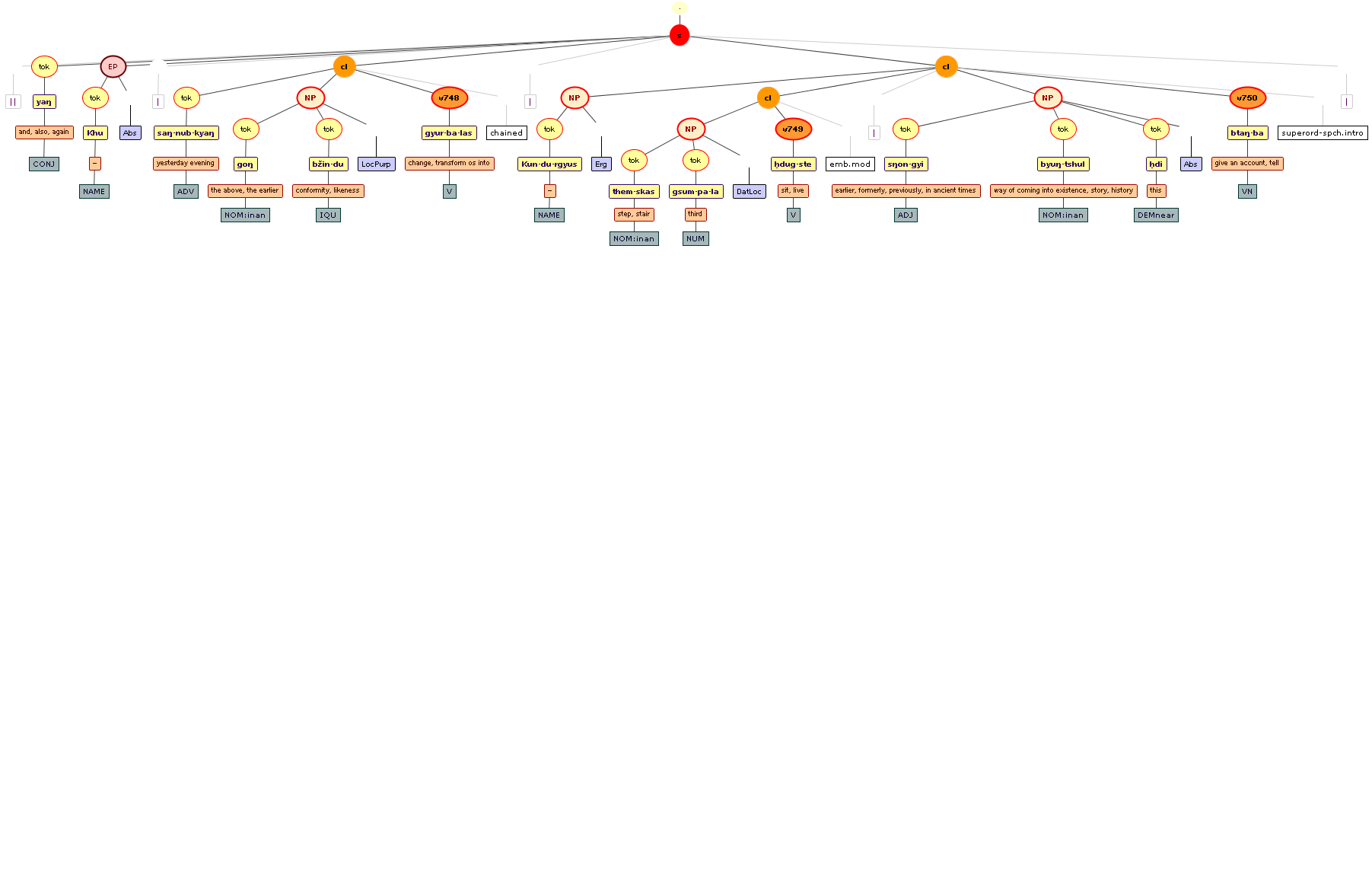
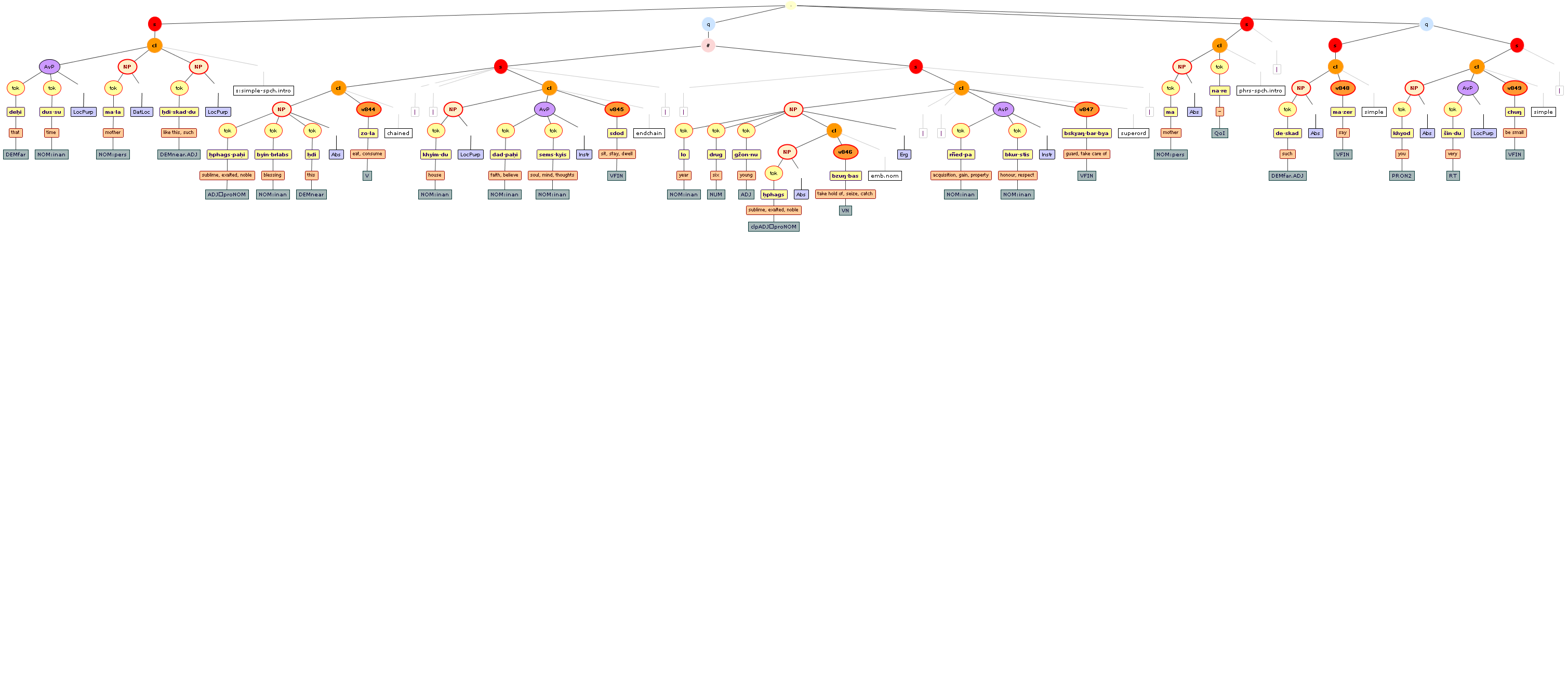
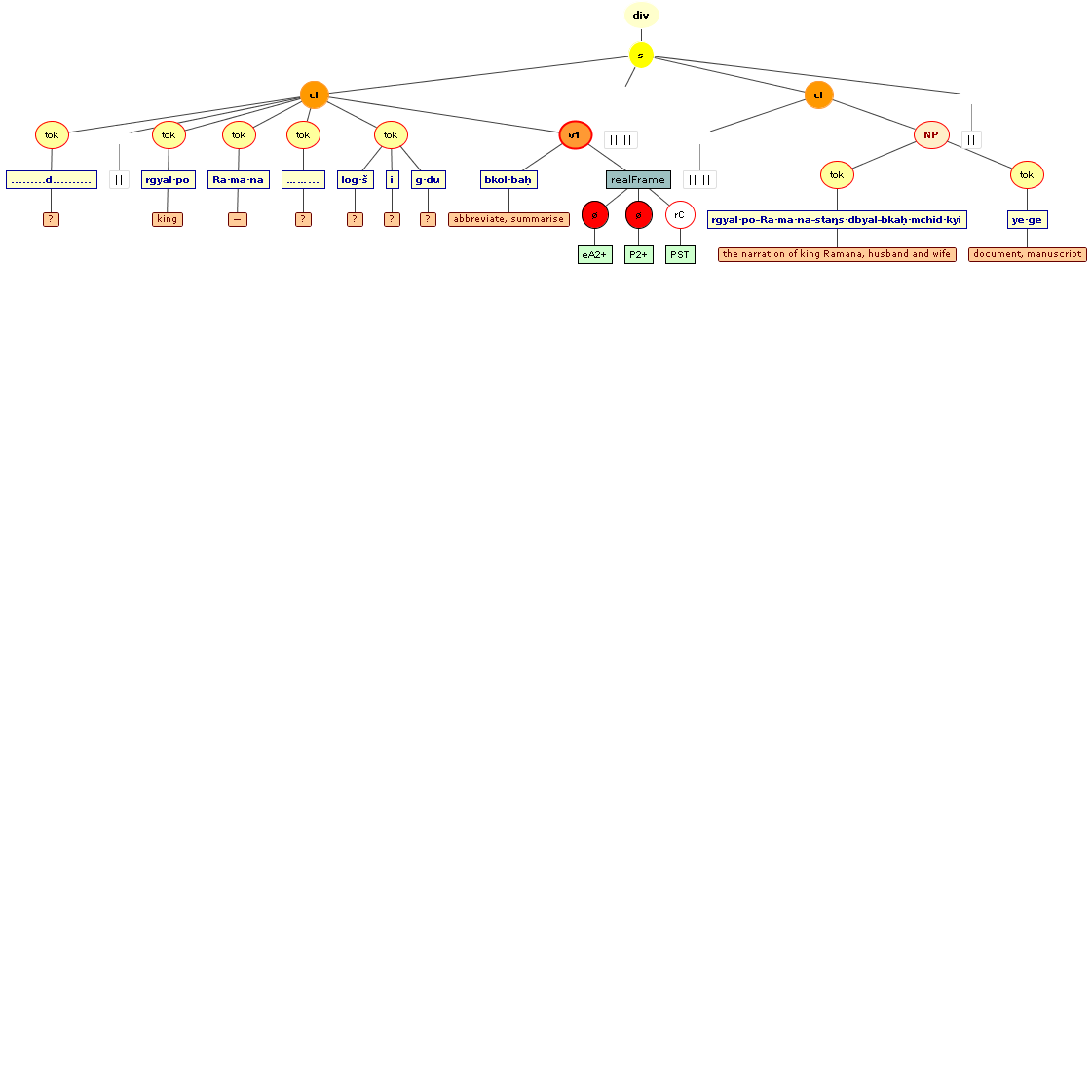
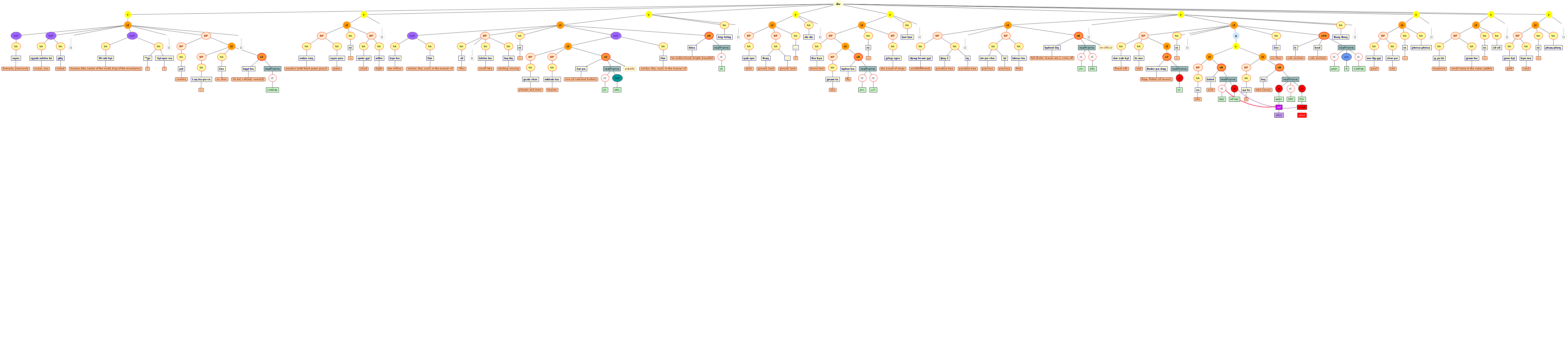
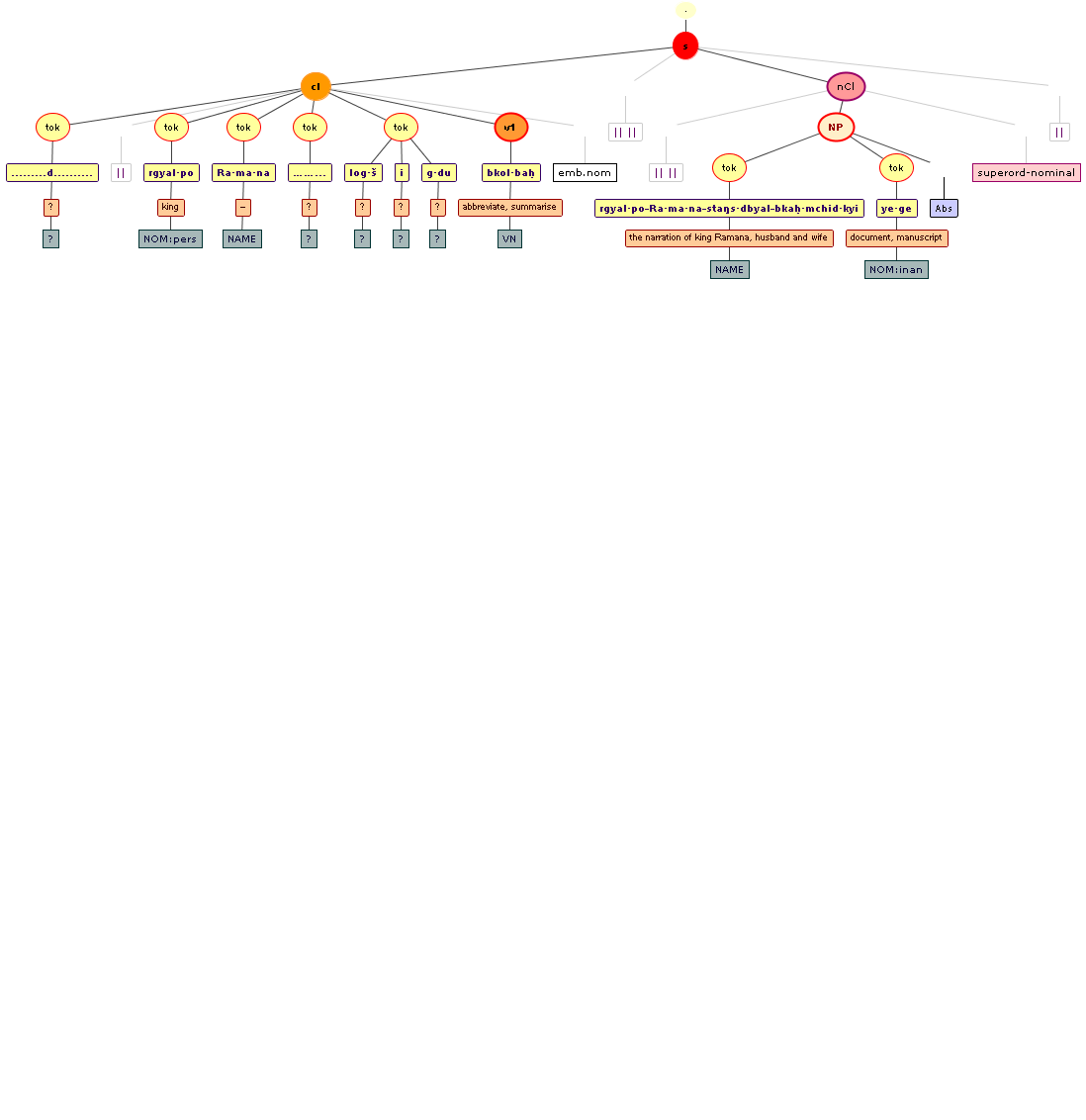
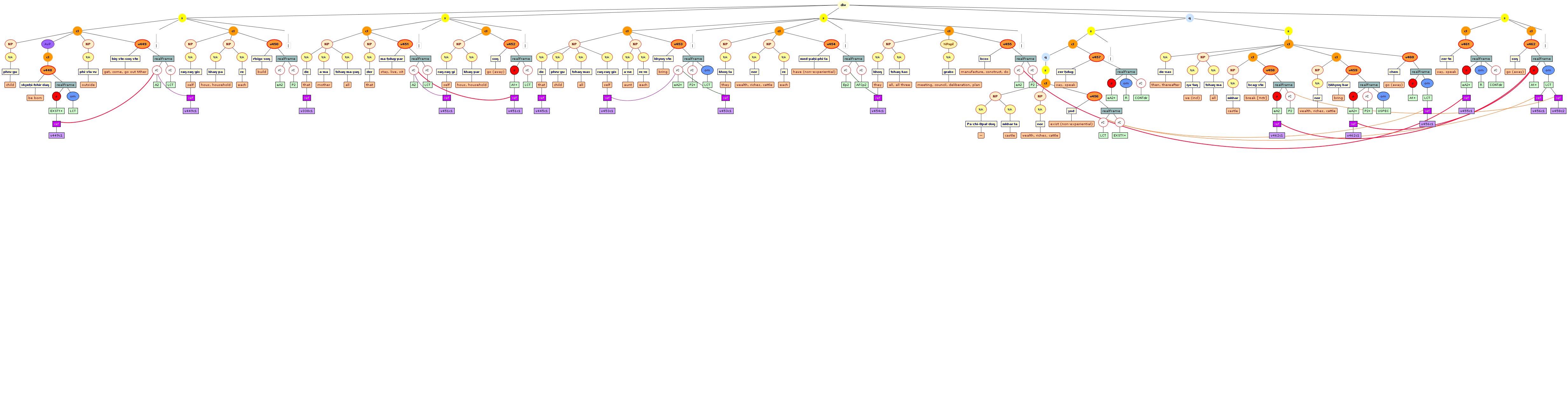
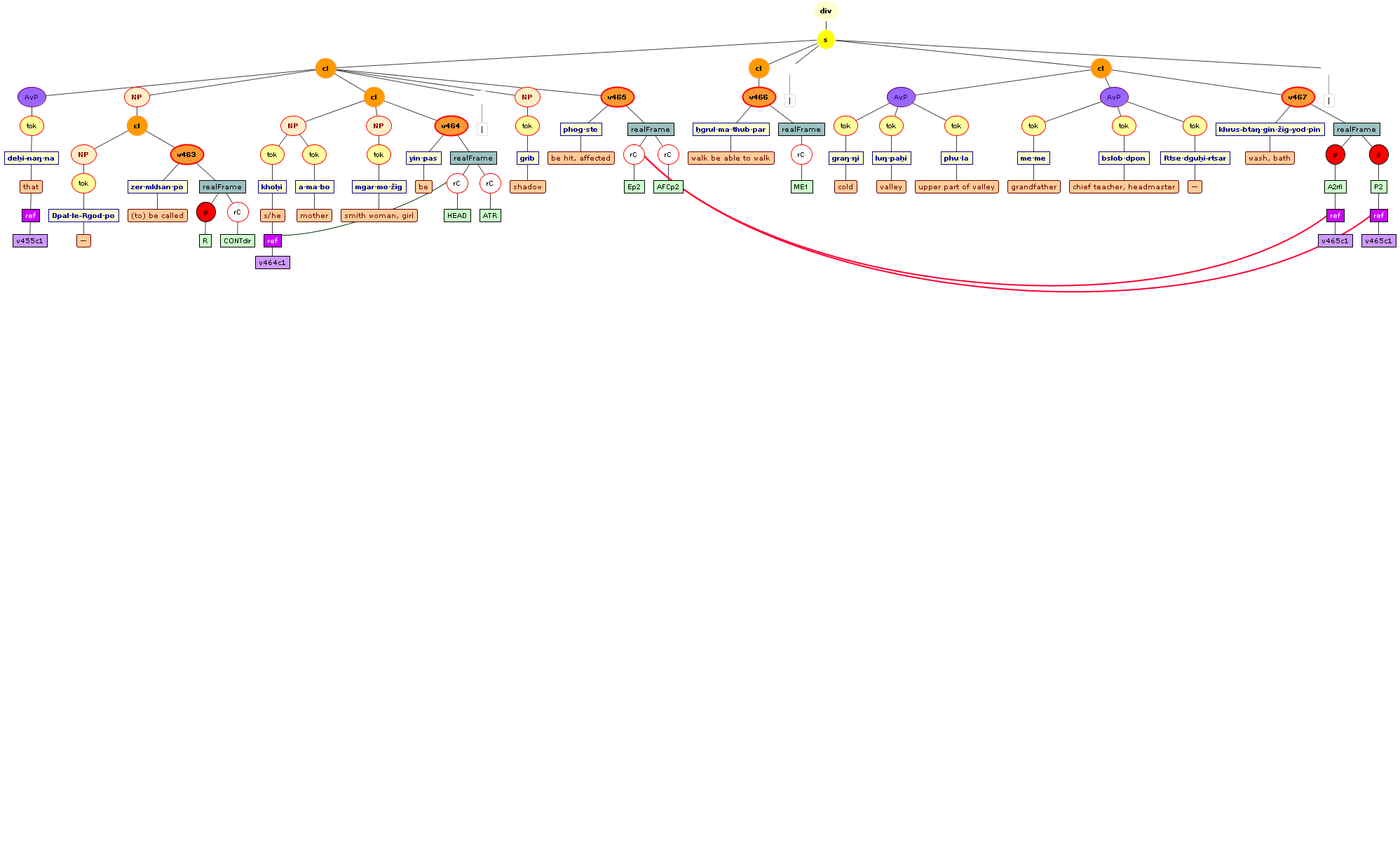
Tree views
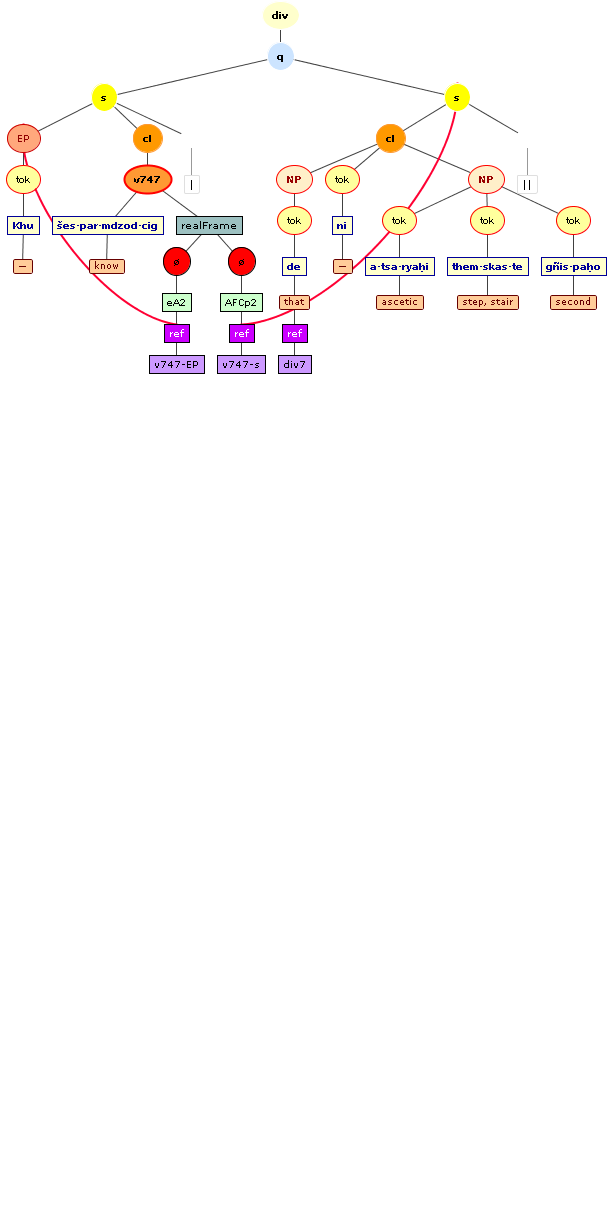
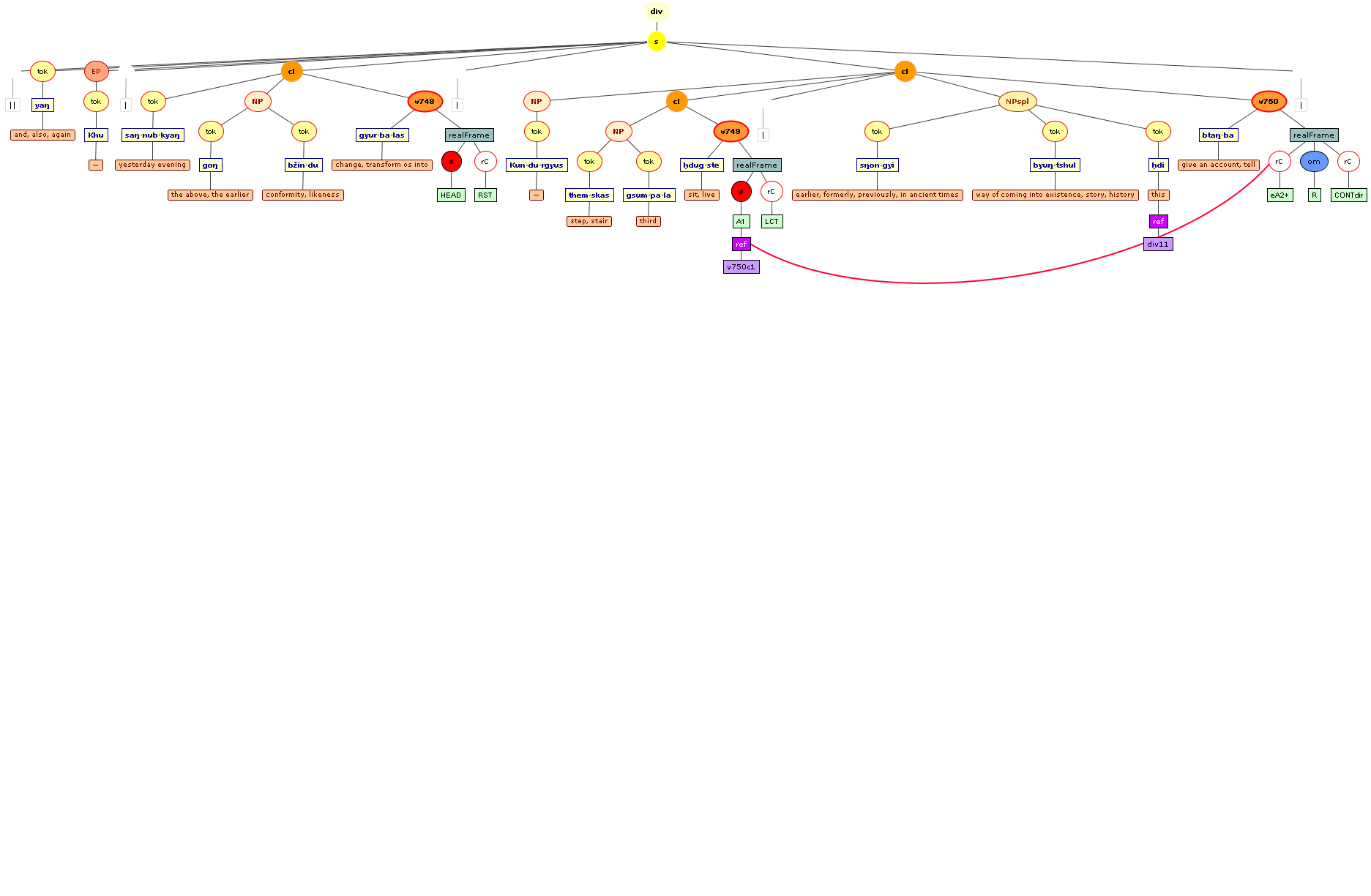
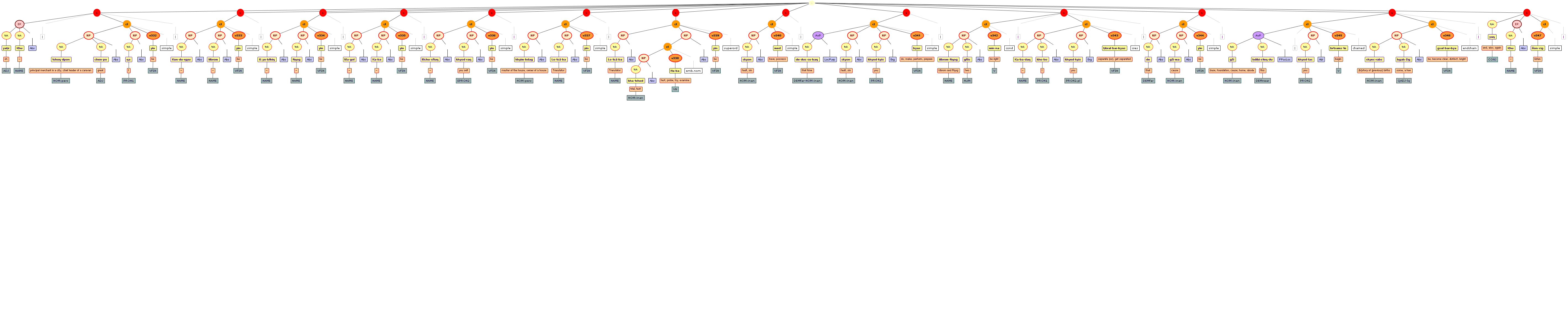
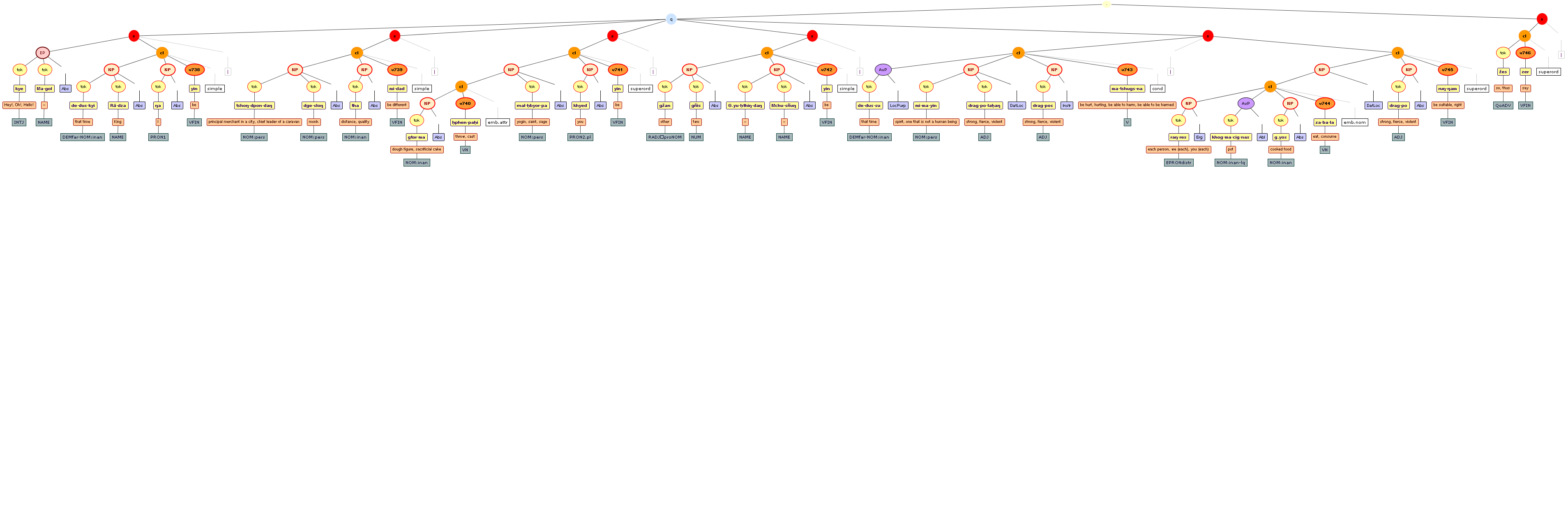
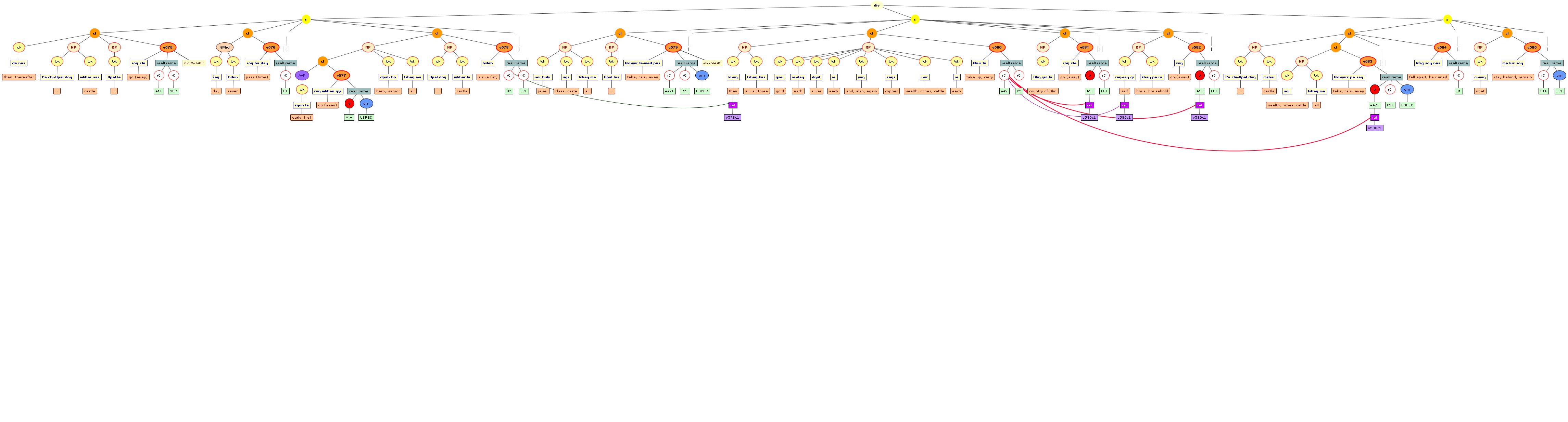
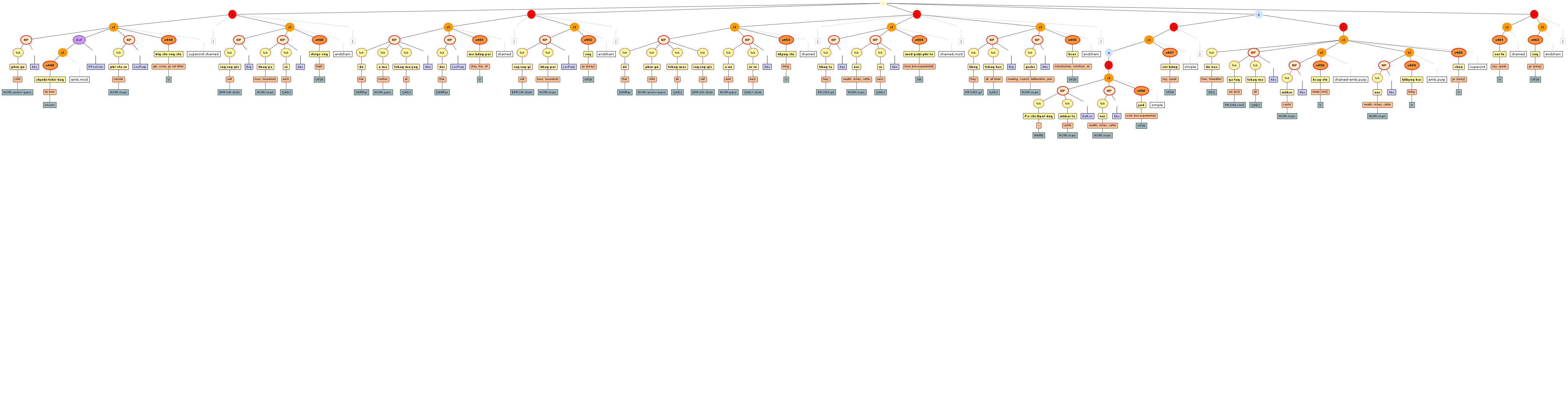
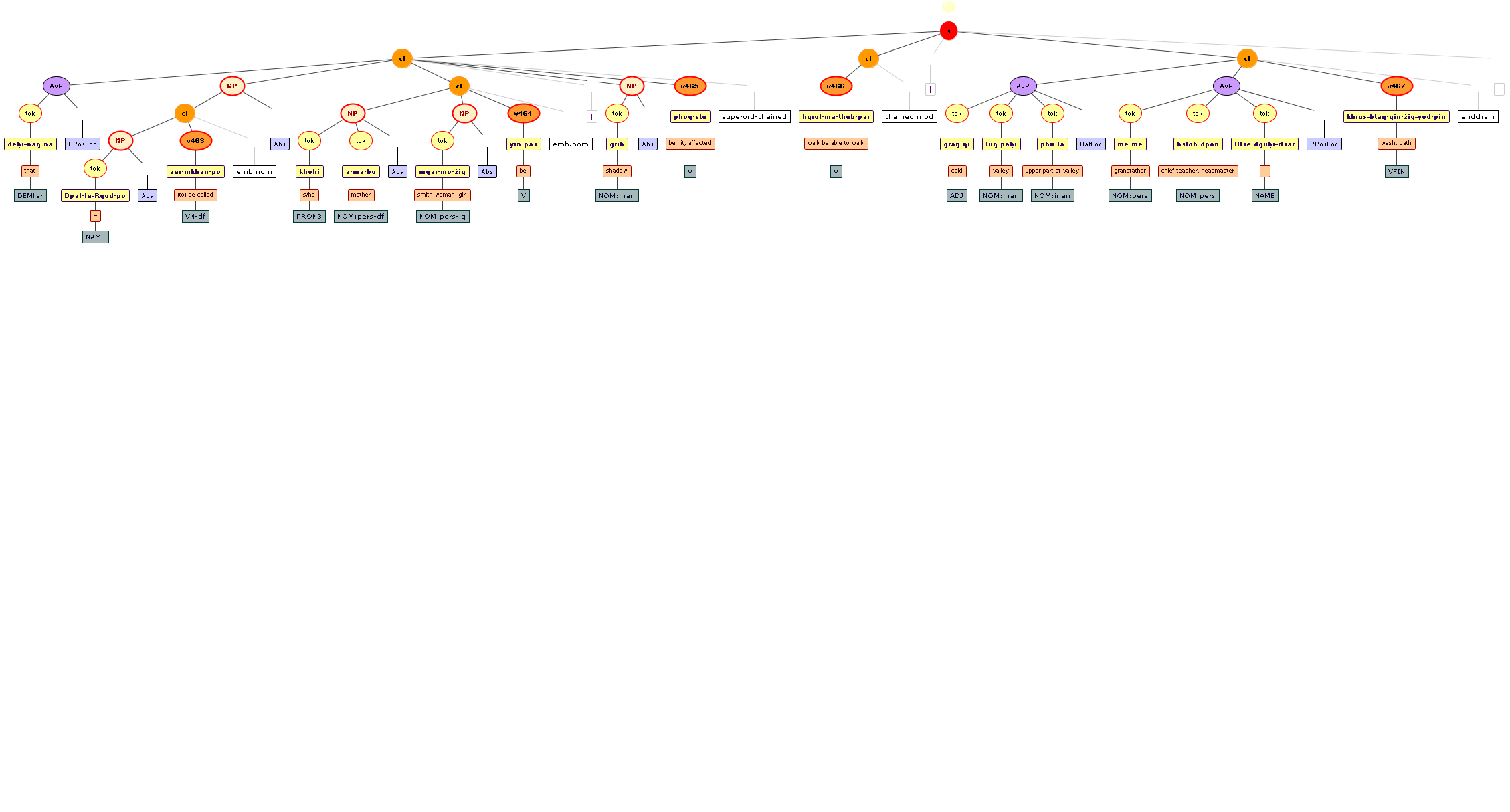
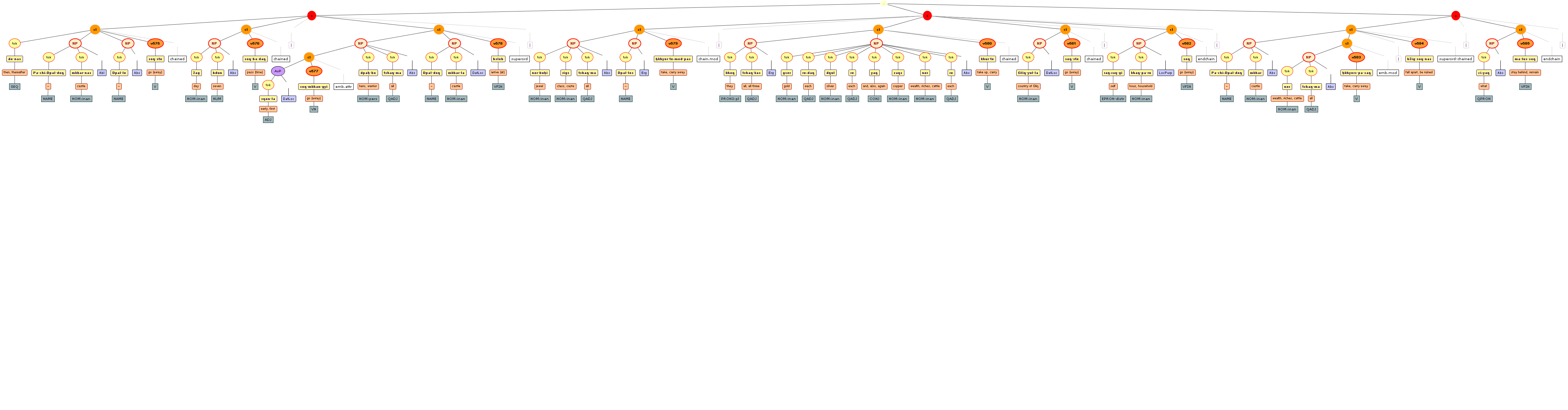
We include some tree graphics (png) generated with the help of the CLaRK tool, which Bettina Zeisler (BZ) used for the annotation. Here again, we faced the problem that CLaRK is not able to open up larger trees, thus we had to divide the text according to the division structure, and sometimes even into smaller parts. Links that go beyond these sections cannot be represented. Further more, the graphics are no longer searchable or dynamic; the dynamic representations in CLaRK itself (very useful for smaller structures) are usually minimised to absolute illegibility. On the other hand, CKaRK allows to redefine the trees for special purposes and to highlight individual properties. BZ has thus designed two colourful sets of trees, one showing the basic information (full structure of sentence, clause with clause categories, ntNode with ntNode categories, case, token, text plus interlinear version, part of speech), the other showing a somewhat reduced structure (sentence, clause, ntNode, token, text and interlinear version) plus the argument structure and the reference-relation of empty or ordinary anaphoric elements to their antecedent. The following colours are currently used for the reference links:
red: empty (obligatory) arguments
orange: omitted (non-obligatory) arguments
blue: demonstrative pronouns
dark green: personal pronouns
purple: emphatic pronouns
yellowish green: pronominal use of adjectives
dark purple: empty argument referring to an implied antecedens
dark green: omitted argument referring to an implied antecedens
black: invalid reference empty argument (the antecedens cannot be decided upon)
grey: NP-internal reference
| top project page field work publications documentation of the annotation scheme |
presentation note on translations metadata tree views CLaRK tree representations (overview) |
CLaRK tree representations (overview)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| top project page field work publications documentation of the annotation scheme |
presentation note on translations metadata tree views CLaRK tree representations (overview) |
Layout: Christoph Singer. Responsible for the content: B. Zeisler. Last modified: 20.12.2009