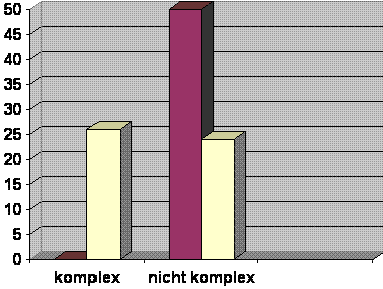Im ersten Fragebogentyp (FB 1) wurde nach einem Motivationspartner gefragt.
Die Informanten wurden bei der Auswahl des Motivationspartners insofern gelenkt, als sie zuerst entscheiden mussten, ob der Stimulus zu einem anderen Wort aus derselben Wortfamilie (Option 1: Derivation) oder zu einer anderen Bedeutung des Stimulus (Option 2: Polysemie) gehört, oder ob sie der Ansicht waren, dass er in andere Wörter zerlegt werden konnte (Option 3: Komposition) oder dass keinerlei Beziehung zu anderen lexikalischen Einheiten besteht (Option 4: Opazität).
Der jeweilige Motivationspartner wurde dann von den Informanten in Freitextfenster eingegeben. Die Antworten wurden in der Auswertung standardisiert und geclustert, wodurch der jeweils am häufigsten genannte Motivationspartner ermittelt werden konnte.
In den Befragungen des FB 1 zum Französischen und
Italienischen wurden jeweils 100 Stimuli bestehend aus Wort + Bedeutung
pro Sprache auf Motiviertheit untersucht. Die Stimuli waren auf
insgesamt 8 Fragebögen verteilt und es wurden Antworten von 30
Sprechern für jeden Fragebogen gewertet. Für die Auswahl der
Ausgangsstimuli wurde eine Kombination der Kriterien Wortfrequenz und
Bedeutungssalienz verwendet. Einteilung der Stimuli nach Faktoren pro Sprache:
Bedeutung mit höchster Salienz [S1]
Bedeutung mit zweithöchster Salienz [S2]
hochfrequente From [hf]
25 Stimuli
25 Stimuli
niedrigfrequente Form [nf]
25 Stimuli
25 Stimuli
Die Tabelle ist so zu lesen, dass jede Wortform (insgesamt 25 hf und 25 nf) jeweils mit zwei Bedeutungen, also S1 und S2 abgefragt wurde.
Beispielstimuli: it. indirettamente [nf] 'tramite altri canali o persone' [S1] und indirettamente [nf] 'in modo non esplicito' [S2]
Die hochfrequenten Wortformen entsprechen den 25 frequentesten Substantiven, Verben, Adjektiven und Adverbien, die auch mit lexikalischer Bedeutung verwendet werden können, aus den Frequenzlisten von Julliand/Brodin/Davidovitch (1970) und Juilland/Traversa (1973), die niedrigfrequenten Wortformen wurden in diesen Frequenzlisten aus den Tranchen mit den Frequenzen 10 (Französisch) bzw. 10-9 (Italienisch) mit einem Randomverfahren ausgewählt.
Die Salienzen der Bedeutungen wurde mithilfe eines Sentence Generation und Definition Task ermittelt. In dieser Befragung mussten die Informanten zu vorgegebenen Wortstimuli eine nicht festgelegte Anzahl von Sätzen bilden, wobei der Stimulus in jedem Satz mit einer anderen Bedeutung verwendet werden sollte. Zusätzlich zu den Sätzen mussten Bedeutungsdefinitionen gegeben werden, die beim Auswerten in Zweifelsfällen bei der Ermittlung der jeweiligen Bedeutung hilfreich sein konnten. Als höchstsalient wurde die Bedeutung gewertet, die am häufigsten genannt wurde, zweithöchst salient entsprechend die am zweithäufigsten genannte Bedeutung.
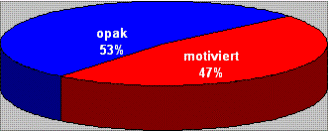
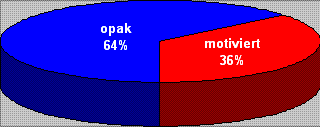
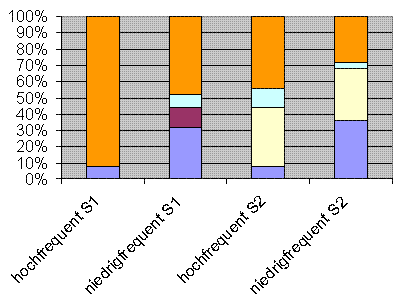
Die Tortendiagramme geben an, wieviel Prozent der abgefragen Stimuli motiviert waren und wieviel Prozent opak. Motiviert sind die Stimuli, wenn eine relative Mehrheit von Informanten dieselbe motivierende lexikalische Einheit nennt.
Französisch
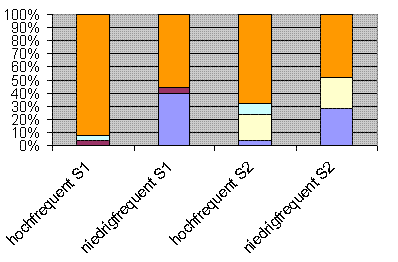
Italienisch
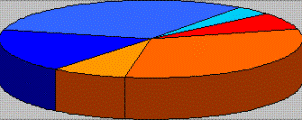
In den folgenden Diagrammen sind die Ergebnisse
differenziert in stark/mittel/schwach motiviert bzw.
stark/mittel/schwach opak. Die Aufteilung in die einzelnen Klassen
erfolgt nach Anzahl der Informanten pro Motivationspartner bzw. Opazität: stark: 20-30 Informanten,
mittel: 10-19 Informanten, schwach: 1-9 Informanten.
Niedrigfrequente Einheiten sind auf Grund ihrer tendenziell größeren formalen Komplexität
leichter motivierbar als hochfrequente.
Formal komplex sind unserer Definition nach Lexien, die entweder das Resultat einer Affigierung oder einer Komposition sind.
Es folgt eine Übersicht der Stimuli aufgrund der Kriterien der
formalen Komplexität und Wortfrequenz. Jede Form wurde zweimal,
jeweils mit der salientesten und der zweitsalientesten Bedeutung
abgefragt, daher zählt bezogen auf die Gesamtanzahl von 100 lexikalischen Einheiten jede der unten
genannten Formen doppelt.
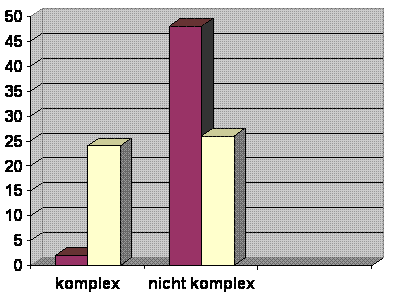
Verteilung der Kriterien Frequenz + Komplexität in unserer Stimulusauswahl für das Französische
Ergebnis: Die Stimuli mit niedrigfrequenten Formen tendieren deutlich stärker zur Komplexität als die mit hochfrequenten
Formen. Innerhalb der Stimuli mit niedrigfrequenten Formen sind jedoch weniger als die Hälfte (24/50=48%) komplex.
Verteilung der Kriterien Frequenz + Komplexität in unserer Stimulusauswahl für das Italienische
Ergebnis: Die Stimuli mit niedrigfrequenten Formen
tendieren stärker zur Komplexität als die mithochfrequenten
Formen, die allesamt nicht komplex sind. Innerhalb derjenigen mit niedrigfrequenten Formen weist aber nur etwas mehr als die Hälfte
(26/50=52%) Komplexität auf, 24/50(=48%) sind nicht komplex.
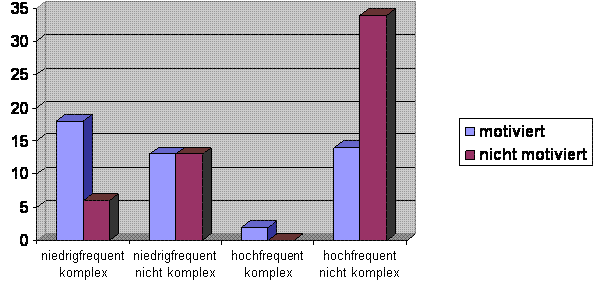
Motiviertheit bezüglich Frequenz und Komplexität
Französisch
Ergebnis: Von den nicht motivierten Stimuli besteht, wie erwartet,
der größte Bereich, nämlich 34%, aus den
hochfrequenten, nicht komplexen Formen. Von den Stimuli mit hochfrequenten
komplexen Formen sind alle motiviert, allerdings beträgt deren
Gesamtzahl nur 2 (und entsprechend auch 2% vom Gesamtanteil), nämlich 2x monsieur jeweils mit der Bedeutung S1 bzw. S2. Von den motivierten Stimuli gehören wiederum 18% zum
niedrigfrequenten komplexen Bereich, aber immerhin auch 14% zum
hochfrequenten nicht komplexen Bereich. Der Grund hierfür liegt in
der unterschiedlichen Salienz der lexikalischen Einheiten (siehe
Hypothese 2). 13% gehören dem niedrigfrequenten nicht komplexen
Bereich an. Es gibt also einen deutlichen Zusammenhang zwischen
Frequenz und Komplexität (24/50 = 48% im Vergleich zu 2/50 = 4%).
Gleichzeitig lässt sich sagen, dass die niedrigfrequenten
Einheiten eher zur Motiviertheit tendieren als die hochfrequenten (31
vs. 16 von insgesamt 47. Damit ist Hypothese 1 sowohl dahingehend
bestätigt, dass niedrigfrequente Einheiten eher zur
Komplexität neigen als hochfrequente, als auch dahingehend, dass
niedrigfrequente Einheiten eher motiviert sind als hochfrequente.
Daraus folgt zudem, dass komplexe Einheiten eher motiviert sind als
nicht komplexe.
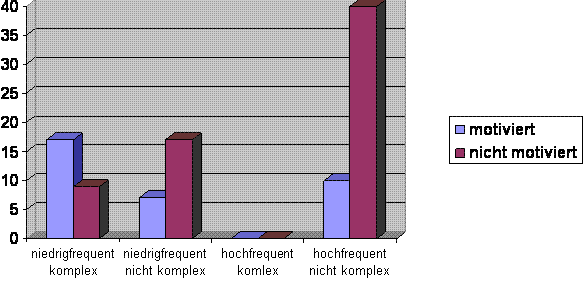
Italienisch
Ergebnis: Von den nicht motivierten Stimuli besteht, wie erwartet, der
größte Bereich, nämlich ca. 61%, aus den
hochfrequenten, nicht komplexen Formen. Es gibt, anders als im
Französischen, unter den hochfrequenten Formen keine komplexen
Formen im Sample.
Von den motivierten Stimuli gehören 50% zum
niedrigfrequenten komplexen Bereich, aber immerhin auch ca. 29% zum
hochfrequenten nicht komplexen Bereich. Der Grund hierfür liegt
wie im Französischen in der unterschiedlichen Salienz der
lexikalischen Einheiten (siehe Hypothese 2). Ca. 21% gehören
dem niedrigfrequenten nicht komplexen Bereich an.
Es gibt also einen deutlichen Zusammenhang zwischen niedriger Frequenz
und hoher Komplexität (52% der niedrig frequenten sind komplex vs.
0% bei den hochfrequenten). Gleichzeitig lässt sich sagen, dass
die niedrigfrequenten Einheiten eher zur Motiviertheit tendieren als
die hochfrequenten (71% = 24 von 34 motivierten gegenüber 29% = 10
von 34 motivierten). (Oder anders: bei den niedrigfrequenten sind 48%
motiviert (24 von 50), bei den hochfrequnten sind nur 20% motiviert (10
von 50).
Damit ist Hypothese 1 sowohl dahingehend bestätigt, dass
niedrigfrequente Einheiten eher zur formalen Komplexität neigen
als hochfrequente, als auch dahingehend, dass niedrigfrequente
Einheiten eher motiviert sind als hochfrequente.
Hypothese 2
Bei den hochfrequenten Einheiten ist, wenn diese durch eine andere Bedeutung desselben Wortes motiviert wird, die
zweitsalienteste Bedeutung (S2) durch die salienteste (S1) motiviert,
aber nicht umgekehrt.
Französisch
Die Angabe "motiviert durch andere Bedeutung" bedeutet in dieser und der folgenden Legende, dass der Stimulus durch eine andere Bedeutung desselben Wortes motiviert ist, die weder der S1 Bedeutung noch der S2 Bedeutung entspricht.
Ergebnis: Wie sich in der Graphik zeigt, tendieren nicht
nur die Stimuli mit S2 Bedeutung aus dem hochfrequenten Bereich dazu, durch S1
motiviert zu werden, sondern auch die Stimuli mit S2 Bedeutung aus dem
niedrigfrequenten Bereich. Wie erwartet, sind im hochfrequenten Bereich
keine S1-Stimuli durch S2 motiviert, im niedrigfrequenten jedoch
immerhin 3 von 25. Im S1-Bereich spielt dagegen die Motivierung durch
ein anderes Wort aus derselben Wortfamilie die wichtigste Rolle,
genauso im Bereich der niedrigfrequenten S2-Stimuli. Damit ist
Hypothese 2 bestätigt und kann mit Einschränkungen sogar
auf den niedrigfrequenten Bereich angewendet werden.
Italienisch
Ergebnis: Wie sich in den Graphiken zeigt, tendieren die
S2-Stimuli aus dem hochfrequenten Bereich dazu, durch S1 motiviert zu
werden. Die S2-Stimuli aus dem niedrigfrequenten Bereich hingegen,
tendieren, anders als im Französischen, dazu, hauptsächlich
durch ein anderes Wort (allerdings dennoch dicht gefolgt von S1),
motiviert zu werden. Wie erwartet, sind im hochfrequenten Bereich nur
sehr wenige S1-Stimuli (nämlich 1) durch S2 motiviert (aber nicht
keine, wie im Französischen), im niedrigfrequenten Bereich sind
die Verhältnisse genau so. Im S1-Bereich der niedrigfrequenten
spielt die Motivierung durch ein anderes Wort aus derselben Wortfamilie
die wichtigste Rolle, genauso im Bereich der niedrigfrequenten
S2-Stimuli. Damit ist Hypothese 2 bestätigt und kann mit
Einschränkungen sogar auf den niedrigfrequenten Bereich angewendet
werden.
Die motivierten Stimuli der ersten Befragungsrunde wurden gemeinsam mit ihren Motivationspartnern in einem halb-geschlossenen Fragebogentyp (FB 2) gemeinsam mit den Motivationspartnern den Sprechern vorgelegt. Die Aufgabe der Sprecher bestand darin, zwischen den für die semantischen Relationen diagnostischen Satzrahmen auszuwählen, in die zwei Bedeutungsdefinitionen bzw. Synonyme als Variablen eingesetzt waren, und diese Auswahl in einem Freitext zu begründen.
Diagnostische Satzrahmen für pension 'internat' - pension 'petit hôtel':
"internat" est la même chose que "petit hôtel", parce que
= konzeptuelle Identität
"internat" et "petit hôtel" n’ont rien à voir l’un avec l’autre, mais on peut quand même percevoir une certaine similarité entre les deux dans la mesure où
= metaphorische Similarität
"internat" et "petit hôtel" sont, en général, liés dans l’espace et (ou) dans le temps dans la mesure où
= Kontiguität
"internat" est le contraire de "petit hôtel" dans la mesure où
= Kontrast
"internat" et "petit hôtel" sont tous les deux des types de
= kotaxonomische Similarität
"internat" est un type de "petit hôtel" , parce que
= taxonomische Subordination
Il y a plusieurs types de "internat" dont un est "petit hôtel" , parce que
= taxonomische Superordination
"internat" et "petit hôtel" ne sont liés dans aucune des manières proposées, mais
= Jokerrelation
Je ne vois aucune relation entre "internat" et "petit hôtel".
= opak
Die diagnostische Satzrahmen entsprechen allen semantischen Relationen, die in dem Inventar bei Koch/Marzo (2007) vorgesehen sind. Desweiteren gibt es eine Jokerrelation für Informanten, die eine andere Formulierung bevorzugen, und die Möglichkeit semantische Opazität auszuwählen. Dadurch konnte es sein, dass Stimuli, die in FB 1 als motiviert gewertet wurden, durch das Nichtvorliegen einer semantischen Relation in FB 2 als semantisch opak und dadurch insgesamt als opak bewertet wurden.
Bei der Auswertung wurde die Vorauswahl der Informanten mit ihren Freitextformulierungen verglichen. Dabei wurde die Vorauswahl entweder bestätigt oder mit dem Label UNKLAR versehen. In Fällen, in denen die Sprecher im Freitext eine Relation beschrieben, die eindeutig nicht der Vorauswahl, sondern einer anderen Relation entsprach, wurde auch die Vorauswahl der Sprecher korrigiert.
Insgesamt wurden zwei Fragebögen pro Sprache getestet, wobei der Fragebogen für das Französische jeweils 23 und der für das Italienische jeweils 18 Stimuluspaare enthielt. Die unterschiedliche Anzahl der Stimuluspaare ist durch das Ergebnis der Befragung mit FB 1 bedingt. Jeweils 30 Sprecherantworten pro Stimulus wurden gewertet.
Nicht alle Kombinationen aus formalen und semantischen Relationen können überhaupt auftreten.
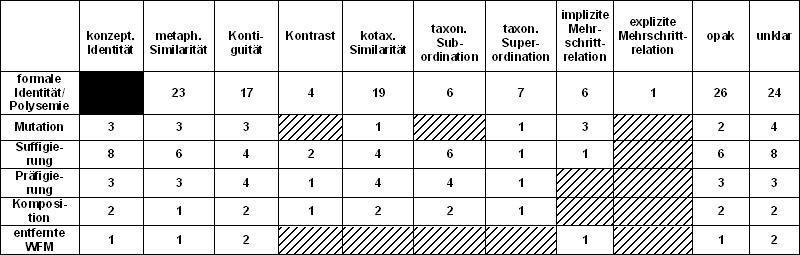
Französisch
Die Zahlen in den Zellen sind als absolute Zahlen zu lesen, sie zeigen pro Stimuluspaar an, welche Typen von semantischen Relationen von den Informanten für das Stimuluspaar und seine jeweilige formale Relation gewählt wurden. Die Zahlen entsprechen nicht den Ergebnissen pro Stimuluspaar (siehe dazu II. 2.2).
In der obersten Zeile sind alle in Koch/Marzo (2007) genannten semantischen Relationen inklusive der (semantischen) Opazität aufgeführt. Außerdem enthält die Tabelle die Spalten implizite und explizite Mehrschrittrelation. Diese Kategorien wurden vergeben, wenn die Informanten Relationen implizit oder explizit über den Umweg anderer Konzepte erstellt haben.
Beispiel: veau 'voiture lourde' - veau 'petit de la vache'
'voiture lourde' et
'petit de la vache' ne sont liés dans aucune des manières proposées, mais
Der Freitext kann so interpretiert werden, dass der Sprecher explizit einerseits eine Kontiguität zwischen 'Kalb' und 'erwachenes Rind' und anderseits eine metaphorische Similarität zwischen 'erwachsenes Rind' und 'lahme Karre' vermittels des Merkmals schwerfällig sieht.
Das Label UNKLAR wurde vergeben, wenn Vorauswahl und Freitext nicht übereinstimmten und der Freitext zudem nicht eindeutig einer der anderen Relationen zugeordnet werden konnte. Insgesamt wurde die Nichtrelation UNKLAR mit allen formalen Relationen kombiniert und sie wurde bei 43 von 46 Stimuli vergeben. Diese hohe Kombinierbarkeit lässt sich dadurch erklären, dass die Informanten anstelle von diagnostischen Sätzen mit Wörtern (wie sie überlicherweise in der Literatur verwendet werden: z.B. A stallion is a kind of horse) Sätze mit zum Teil längeren Bedeutungsdefinitionen in den Leerstellen erhielten, die dadurch schwer verständlich wurden. Diese Vorgehen Bedeutungsdefinitionen anstelle von Wörtern zu verwenden, erwies sich als notwendig, da auch der Fall der Polysemie mit abgefragt wurde. Zudem kommt verständniserschwerend hinzu, dass sich einige der Satzrahmen lediglich für Substantive als Füllwörter eignen. Diese Maßnahme lässt sich dadurch begründen, dass die Vorauswahl der Stimuli Substantive, Verben, Adjektive und Adverbien umfasste, die in einem abgefragt werden mussten, da wiederum zu wenig motivierte Stimuli für eine Aufsplittung der Fragebögen nach Wortarten vorlagen.
Die formalen Relationen, die zwischen den vorgegebenen Stimuluspaaren bestehen, sind in der ersten Spalte aufgeführt. Entfernte Wortfamilienmitgliedschaft (WFM) wurde ausgewählt, wenn sich der motivierte Stimulus und der Motivationspartner nicht mit Hilfe der üblichen Wortbildungsverfahren relationieren ließen (renforcer-force mit jeweils zwei Bedeutungen).
Ergebnis: Sieht man von den opaken und unklaren Fällen ab, so überwiegt deutlich die Kombination <Polysemie.metaphorische Similarität> gefolgt von <Polysemie.kotaxonomische Similarität> und <Polysemie.Kontiguität>. Für die wenigen abgefragten formalen Relationen lässt sich feststellen, dass - entgegen den Erwartungen - für die Sprecher beinahe alle semantischen Relationen mit allen formalen Relationen kombinierbar sind. Dieser Befund ist natürlich noch kein Beweis für die Wahrheit oder Falschheit Ausgangshypothese, da dafür sehr viel mehr Stimuluspaare und Sprachen untersucht werden müssten. Insgesamt lässt sich auch sagen, dass bei dieser Art des Tests die größte Schwierigkeit für die Sprecher darin bestand, Aussagen für die vorgegebenen Stimulusbedeutungen zu machen. Die Freitextbegründungen zeigten oft auf, dass die Sprecher von einer von der Stimulusbedeutung leicht verschiedenen Bedeutung her argumentierten. Diesen Problemen wurde versucht bei der Auswertung Rechnung zu tragen, weshalb es auch zu der hohen Anzahl von Unklarfällen kam.
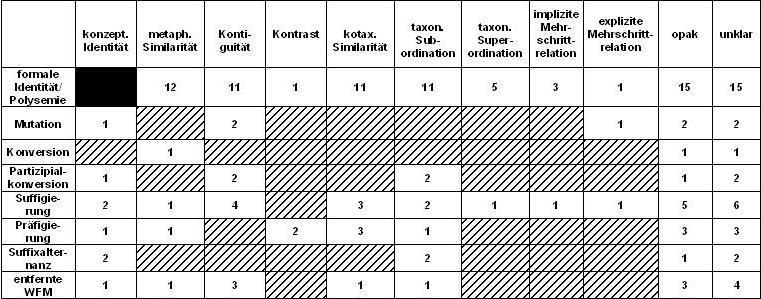
Italienisch
Ergebnis: Im Gegensatz zum Französischen zeigt sich im Italienischen anscheinend eine wesentlich geringere Kombinierbarkeit. Dieser Unterschied könnten in vielen Faktoren begründet sein: Ausgangsstimuli, Sprecher oder Interpretationen der Auswerter. Ohne Berücksichtigung der unklaren und opaken Fällen ergibt sich hier auch ein ähnliches Bild wie im Französischen <Polysemie.metaphorische Similarität> ist der Kombinationsgewinner, dicht gefolgt von <Polysemie.kotaxonomische Similarität>, <Polysemie.taxonomische Subordination> und <Polysemie.Kontiguität>.
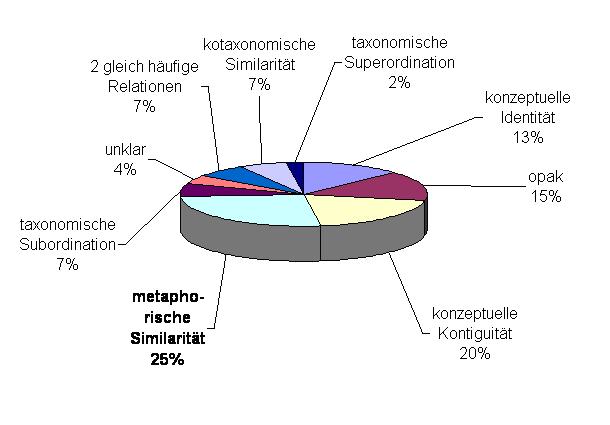
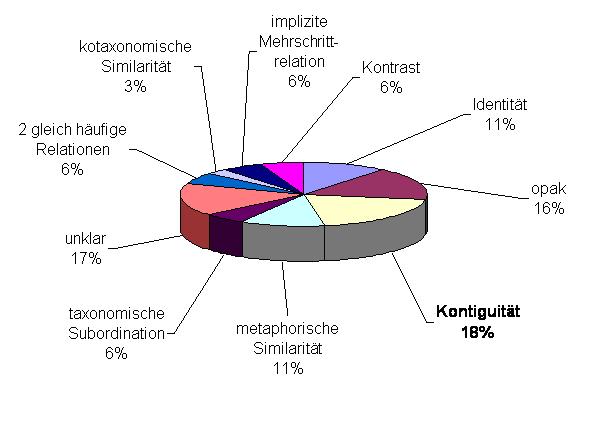
Die semantischen Relationen sind in den beiden untersuchten Sprachen ähnlich verteilt.
Französisch
Italienisch
Ergebnis
In den Tortendiagrammen wurden jeweils die relativ häufigsten Relationen zusammengezählt. So konnte es sein, dass zum Teil zwei Relationen gleich häufig waren, diese Fälle wurden ebenfalls zusammengezählt, sie sind aber in der Ergebnisübersichtüber über die Stimuluspaare einzeln aufgeführt. Wenn man nur die Mengen an Antworten betrachtet, die sich einer der Ausgangsrelationen zuordnen ließen, so fällt auf, dass für den untersuchten Konzeptbereich im Französischen die metaphorische Similarität überwiegt, für das Italienische hingegen, wie das auch zu erwarten war, die Kontiguität. Insgesamt gesehen, sind in beiden Sprachen Kontiguität, metaphorische Similarität und Identität am stärksten vertreten. Dass die Identität so häufig ist, lässt sich so erklären, dass für die Informanten, die den FB II bearbeiteten, die Bedeutungsunterschiede, die mit Hilfe von FB I gemacht wurden, häufig nicht so deutlich zu erkennen waren.
Alphonse Juilland, Dorothy Brodin und Catherine Davidovitch (1970). Frequency dictionary of French words, The Hague: Mouton de Gruyter.
Alphonse Juilland und Vincenzo Traversa (1973). Frequency dictionary of Italian words, The Hague: Mouton de Gruyter.
Peter Koch und Daniela Marzo (2007): "A two-dimensional approach to the study of motivation in lexical typology and its first application to French high-frequency vocabulary", Studies in Language 31:2, 259-291.