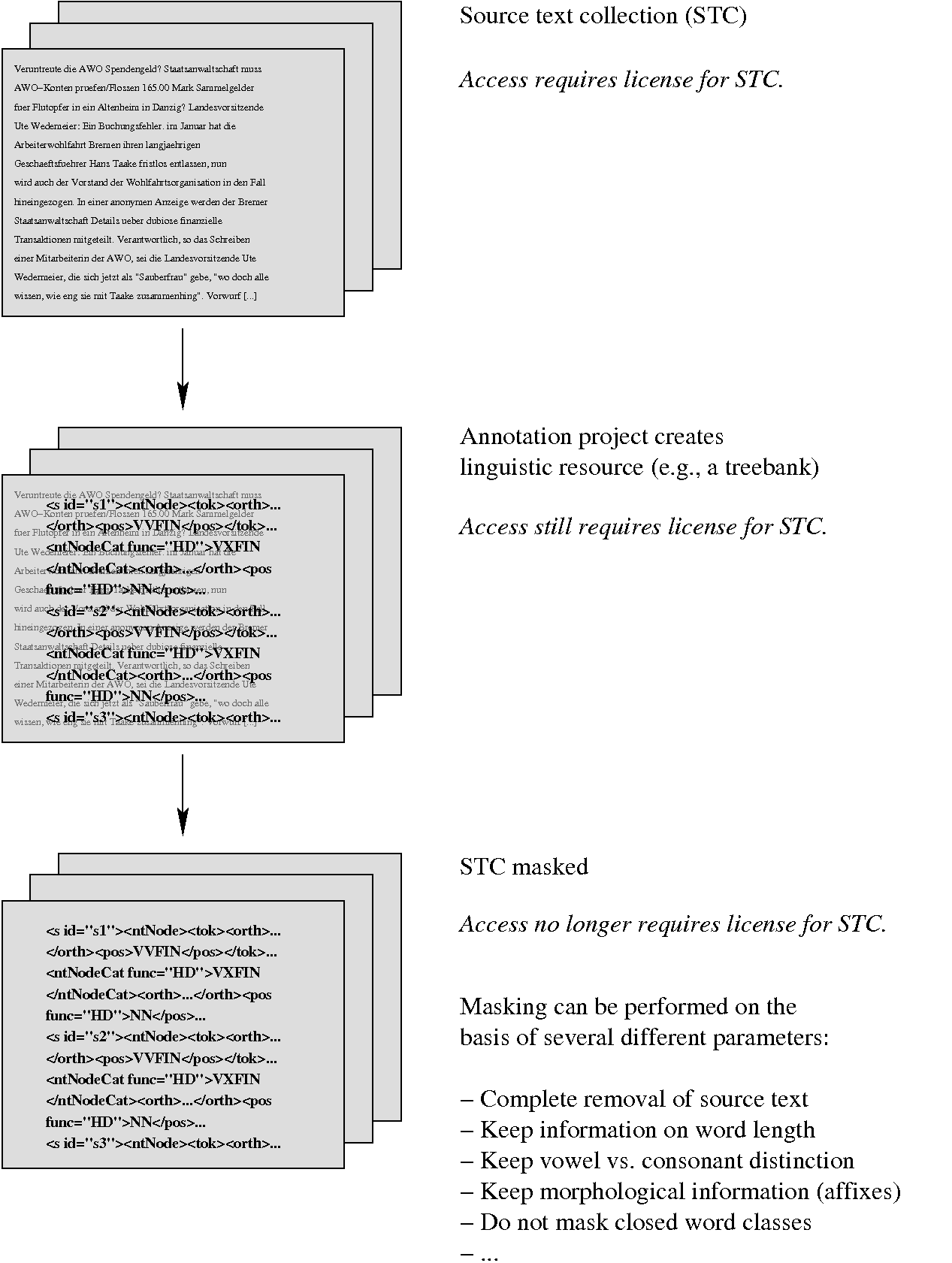
| Part-of-speech (POS): | VVFIN | ART | NN | NN | |
| Original sentence: | Veruntreute | die | AWO | Spendengeld | ? |
| | | | | | | | | | | |
| Characters replaced with [xX9]: | Xxxxxxxxxxx | xxx | XXX | Xxxxxxxxxxx | ? |
| | | | | | | | | | | |
| Random characters: | Sololplaoka | tao | UJA | Wkirdomgirk | ? |
| | | | | | | | | | | |
| Random characters, keep affixes, keep closed word classes: | Verildniite | die | AJE | Storparpamb | ? |